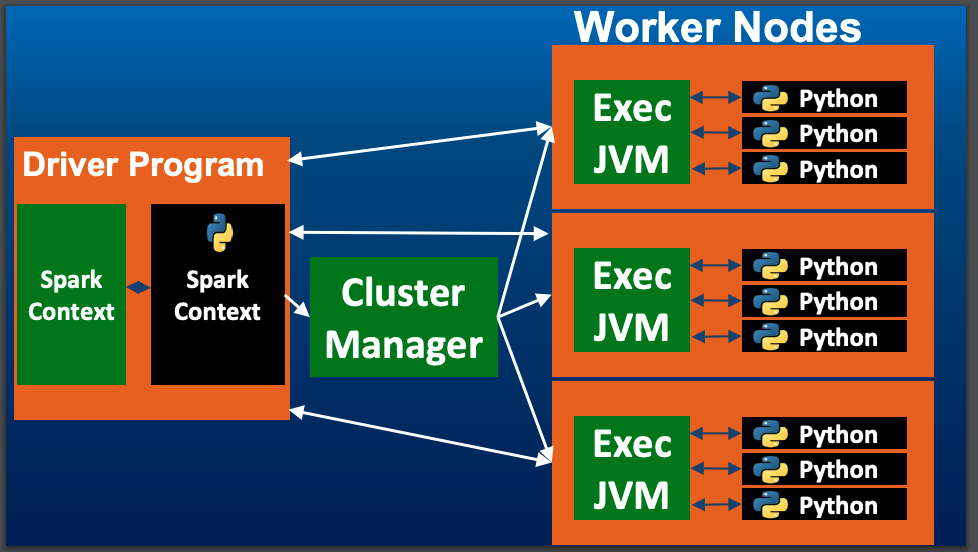
- 유실된 파티션이 있을 때 스파크가 RDD의 처리 과정을 다시 계산하여 자동으로 복구할 수 있다.
- Discover where to start on failed partition.
ex)
integer_RDD.glom().collect()
glom(): to check how the data are partitioned across the cluster of nodes.
collect(): Spark collect() and collectAsList() are action operation that is used to retrieve all the elements of the RDD/DataFrame/Dataset (from all nodes) to the driver node
for k,v in pairs_RDD.groupByKey().collect(): print "Key:", k, ",Values:", list(v)
Out[]: Key: A , Values: [1] Key: ago , Values: [1] Key: far , Values: [1, 1] Key: away , Values: [1] Key: in , Values: [1] Key: long , Values: [1] Key: a , Values: [1]
5) Spark Transformations
-RDD are immutable (no transactional)
-Never modify RDD in place.
-Transform RDD to another RDD to final result (by reducer)
-Create RDD
1)map: apply function to each element of RDD
함수를 적용하는 것으므로 이 트랜스포메이션 자체로는 아무런 동작을 하지 않는다! 수행 계획을 세울뿐..
def lower(line):
return line.lower()
lower_text_RDD = text_RDD.map(lower)
partitions are chunks of our data.
Partitions -> Map() -> Partitions (between same size of partitions)
-flatMap
def split_words(line):
return line.split()
words_RDD = text_RDD
flatMap(split_words)
words_RDD.collect()
-Transformations
map(func)
Return a new distributed dataset formed by passing each element of the source through a functionfunc.
filter(func)
Return a new dataset formed by selecting those elements of the source on whichfuncreturns true.
flatMap(func)
Similar to map, but each input item can be mapped to 0 or more output items (sofuncshould return a Seq rather than a single item).
mapPartitions(func)
Similar to map, but runs separately on each partition (block) of the RDD, sofuncmust be of type Iterator<T> => Iterator<U> when running on an RDD of type T.
mapPartitionsWithIndex(func)
Similar to mapPartitions, but also providesfuncwith an integer value representing the index of the partition, sofuncmust be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T.
sample(withReplacement,fraction,seed)
Sample a fractionfractionof the data, with or without replacement, using a given random number generator seed.
union(otherDataset)
Return a new dataset that contains the union of the elements in the source dataset and the argument.
intersection(otherDataset)
Return a new RDD that contains the intersection of elements in the source dataset and the argument.
distinct([numPartitions]))
Return a new dataset that contains the distinct elements of the source dataset.
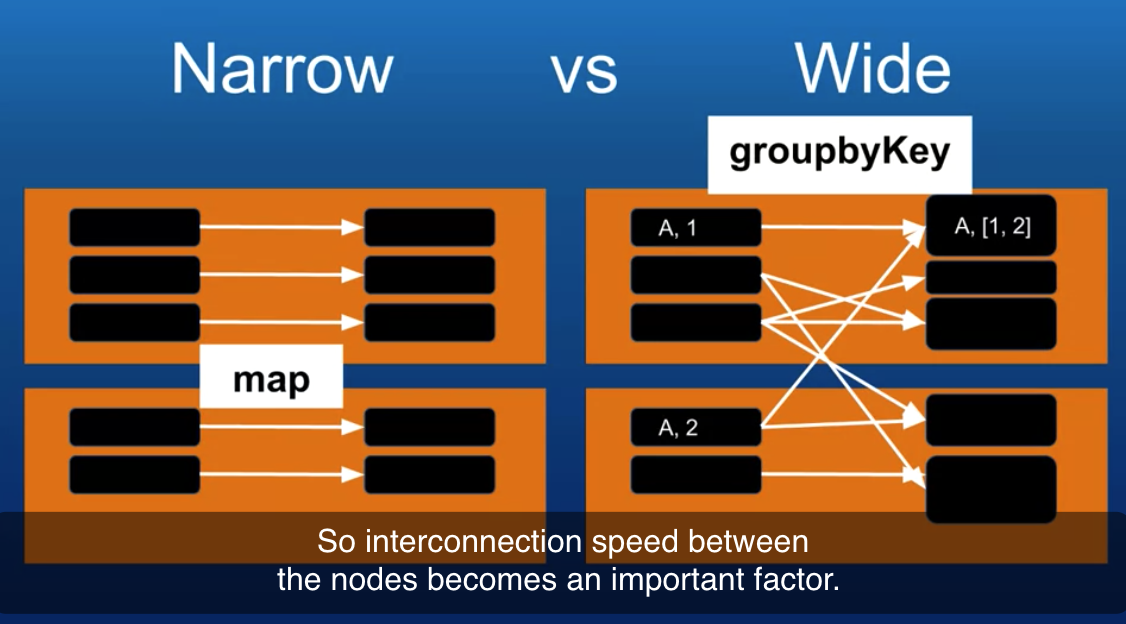
groupByKey([numPartitions])
가장 많이 사용하는 메서드로, 값을 집계하려면 셔플을 해야한다.
When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. Note:If you are grouping in order to perform an aggregation (such as a sum or average) over each key, usingreduceByKeyoraggregateByKeywill yield much better performance. Note:By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optionalnumPartitionsargument to set a different number of tasks.
pairs_RDD.groupByKey().collect()
"shuffle" through the different nodes while groupbykey works.
reduceByKey(func, [numPartitions])
하나의 값이 나올때까지 반복적으로 키-값 쌍의 값에 이진 함수를 적용. 이 메서드는 스칼라 tuple2로 정의된 key-value 쌍의 RDD만 가능하다. 그러므로 이 연산을 수행하기 전에 RDD를 map() 메서드를 이용해서 먼저 키-벨류로 변환해줘야한다. When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce functionfunc, which must be of type (V,V) => V. Like ingroupByKey, the number of reduce tasks is configurable through an optional second argument.
When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like ingroupByKey, the number of reduce tasks is configurable through an optional second argument.
sortByKey([ascending], [numPartitions])
When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the booleanascendingargument.
join(otherDataset, [numPartitions])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported throughleftOuterJoin,rightOuterJoin, andfullOuterJoin.
cogroup(otherDataset, [numPartitions])
When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>, Iterable<W>)) tuples. This operation is also calledgroupWith.
cartesian(otherDataset)
When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements).
pipe(command,[envVars])
Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process's stdin and lines output to its stdout are returned as an RDD of strings.
coalesce(numPartitions)
Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset.
by glom().collect() we can find our this data set was split in 4 partitions
repartition(numPartitions)
Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. ( even distributions of your cluster) <-> Coaleace does locally 1) Try with coalesce.. if the local merging of partitions is good enough for my app 2) Use repartition
repartitionAndSortWithinPartitions(partitioner)
Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than callingrepartitionand then sorting within each partition because it can push the sorting down into the shuffle machinery.
INSERTINTO`topic` (`id`, `title`, `description`, `author`, `created`) VALUES(1, 'About JavaScript', '<h3>Desctiption</h3>\r\n<p>JavaScript is a dynamic computer programming language. It is most commonly used as part of web browsers, whose implementations allow client-side scripts to interact with the user, control the browser, communicate asynchronously, and alter the document content that is displayed.</p>\r\n<p>\r\nDespite some naming, syntactic, and standard library similarities, JavaScript and Java are otherwise unrelated and have very different semantics. The syntax of JavaScript is actually derived from C, while the semantics and design are influenced by the Self and Scheme programming languages.\r\n</p>\r\n<h3>See Also</h3>\r\n<ul>\r\n <li><a href="http://en.wikipedia.org/wiki/Dynamic_HTML">Dynamic HTML and Ajax (programming)</a></li>\r\n <li><a href="http://en.wikipedia.org/wiki/Web_interoperability">Web interoperability</a></li>\r\n <li><a href="http://en.wikipedia.org/wiki/Web_accessibility">Web accessibility</a></li>\r\n</ul>\r\n', 'egoing', '2015-03-31 12:14:00');
INSERTINTO`topic` (`id`, `title`, `description`, `author`, `created`) VALUES(2, 'Variable and Constant', '<h3>Desciption</h3>\r\n\r\nIn computer programming, a variable or scalar is a storage location paired with an associated symbolic name (an identifier), which contains some known or unknown quantity or information referred to as a value. The variable name is the usual way to reference the stored value; this separation of name and content allows the name to be used independently of the exact information it represents. The identifier in computer source code can be bound to a value during run time, and the value of the variable may thus change during the course of program execution.\r\n\r\n<h3>See Also</h3>\r\n<ul>\r\n<li>Non-local variable</li>\r\n<li>Variable interpolation</li>\r\n</ul>\r\n', 'k8805', '2015-05-14 10:04:00');
INSERTINTO`topic` (`id`, `title`, `description`, `author`, `created`) VALUES(3, 'Opeartor', '<h2>Operator</h2>\r\n<h3>Description</h3>\r\n<p>Programming languages typically support a set of operators: constructs which behave generally like functions, but which differ syntactically or semantically from usual functions</p>\r\n<p>Common simple examples include arithmetic (addition with +, comparison with >) and logical operations (such as AND or &&). </p>\r\n', 'egoing', '2015-06-18 05:00:00');