Spark Concept 1)
Before we start..
1) shortcoming of Mapreduce,
- Read from disk for each MapReduce job.
- Only native Java programming interface.
2) so here we have Spark!
- Same features of Mapreduce and more.
- Capable of reusing Hadoop ecosystem like HDFS, YARN..
- lot more easier to build data analysis pipeline.
- In-memory caching of data, specified by the user
- 스파크는 실행 엔진으로 맵리듀스를 사용하지 않고, 클러스터 기반으로 작업을 실행하는 자체 분산 런타임 엔진이 있다.
- 매번 디스크에서 데이터 셋을 읽는 맵리듀스 워크플로우에 비해 10배 혹은 더 빠른 성능.
- DAG엔진을 제공하여 연산자 중심의 파이프라인을 처리해서 사용자를 위한 단일 잡으로 변환한다.
- MLlib, GraphX, Spark Streaming, Spark SQL 모듈은 아파치 프로젝트에 포함된다.
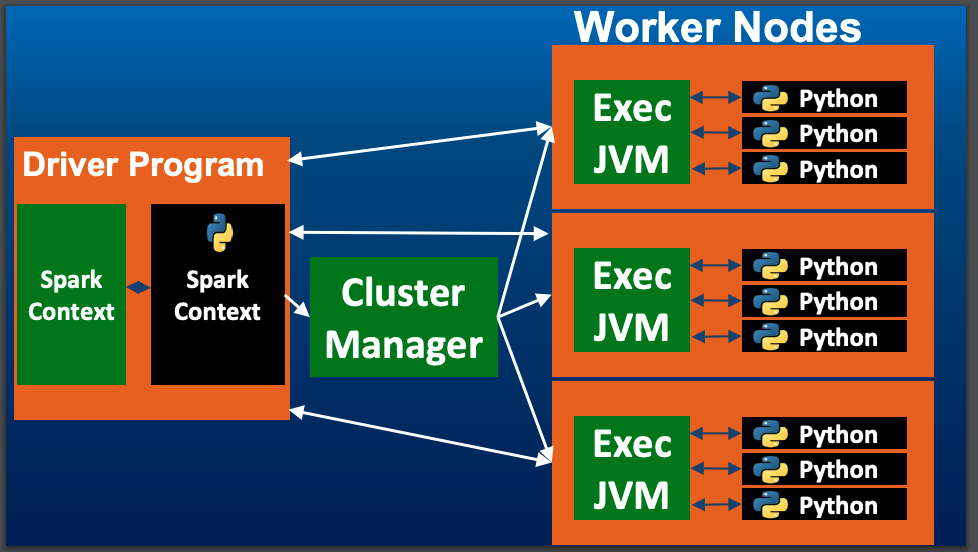
3) Architecture of Spark
- Worker Node:
Spark Executor Java VM <-> interface to HDFS
- Spark assign mapping stage, having data read from HDFS process in memory, results stored as one RDD.
- If running pyspark, data goes to python from the java vm for processing.
- Cluster Manager: Yarn/Standalone Provision/Restart Workers.
-> Standalone for restarts node when the other node is dead.
- Driver Program: Spark context. this is the interface to cluster manager <-> worker nodes.
SC is object which defines how Spark is access to the cluster.
- Context is the 'gateway' for us to connect to our spark instance and submit jobs.
- Submit jobs mean execute command on the shell.
- spark context with the variable 'sc' to read data into spark.
4) RDD(Resilient Distributed Datasets)
- 'the way' in spark to store my data.
- 클러스터에 있는 다수의 머신에 분할되어 저장된 읽기 전용 컬렉션.
- 스파크 프로그램은 하나 혹은 그 이상의 RDD를 입력받고 일련의 변환 작업을 거쳐 목표 RDD 집합으로 변형된다.
- 이 과정에서 결과를 계산하거나 영구 장소에 저장하는 '액션' 이 수행된다.
- RDD로 데이터를 로드하거나 transformation 변형 연산을 수행해도 실제로 데이터는 '처리'되지 않는다. 계산을 위한 수행 '계획'이 만들어진다. 실제 계산은 액션을 호출할 때 수행된다.
- RDDs are created by starting with a file in the Hadoop file
RDD를 만드는 3가지 방법
1) 객체의 인메모리 컬렉션으로 생성
val params = sc.parallelize(1 to 10)
val result = params.map(performExpensizeComputation) 이 함수는 입력값을 병렬로 실행한다. 병렬 처리의 수준은 spark.default.parallelism 속성으로 결정되고, 기본값은 스파크 잡 실행 위치에 따라 달라진다(?)
로컬에서 실행하면 컴퓨터의 코어수, 클러스터에서 수행하면 클러스터의 모든 executor의 토털 core 수에 따라 달라진다.
ex)
integer_RDD = sc.parallelize(range(10),3)
3 numbers of partition and sc.parallelize: function gives you back a reference to your RDD.
2) HDFS와 같은 기존 외부 저장소의 데이터셋을 사용
val text: RDD[string] = sc.textFile(inputPath)
hdfs의 경우 1 hdfs block, 1 spark partition이다.
3) 기존의 RDD를 변환
스파크는 RDD에 트랜스포메이션, 액션이라는 두 종류의 연산자를 제공한다.
트랜스포메이션은 기존 RDD에서 새로운 RDD를 생성한다.
반면 액션은 특정 RDD를 계산하여 어떤 결과를 만들어낸다.
스파크는 lazy 해서 트랜스포메이션이 적용된 RDD에 액션이 수행될때까지는 아무런 동작을 하지 않는다.
- Dataset is like a variable/object in programming.
- Data storage is created from HDFS, HBase, Json..
-> HDFS Hive
- 'Distributed' across the cluster of machines.
- Data are divided in partitions. Spark does not process data by line but as a chunks.
- Partitions -> machines.
- Resilient (not failing). Recover from errors node failure, slow processes.
- 유실된 파티션이 있을 때 스파크가 RDD의 처리 과정을 다시 계산하여 자동으로 복구할 수 있다.
- Discover where to start on failed partition.
ex)
integer_RDD.glom().collect()
glom(): to check how the data are partitioned across the cluster of nodes.
collect(): Spark collect() and collectAsList() are action operation that is used to retrieve all the elements of the RDD/DataFrame/Dataset (from all nodes) to the driver node
- read text into spark
text_RDD = sc.textFile('/usr/hmc/input/testfile1')
- wordcount example
function1)
def split_words(line):
return line.split()
words_RDD = text_RDD.flatMap(split_words)
words_RDD.collect()
flatMap: apply function to each of the element of our RDD.
output[]: [u'A', u'long', u'time', u'ago', u'in', u'a', u'galaxy', u'far', u'far', u'away']
function2)
def create_pair(word):
return (word,1)
pairs_RDD=text_RDD.flatMap(split_words).map(create_pair)
pairs_RDD.collect()
output: [('word',numofword),...] output is key value pair!
Out[]: [(u'A', 1), (u'long', 1), (u'time', 1), (u'ago', 1), (u'in', 1), (u'a', 1), (u'galaxy', 1)
pairs_RDD.groupByKey().collect()
for k,v in pairs_RDD.groupByKey().collect(): print "Key:", k, ",Values:", list(v)
Out[]: Key: A , Values: [1] Key: ago , Values: [1] Key: far , Values: [1, 1] Key: away , Values: [1] Key: in , Values: [1] Key: long , Values: [1] Key: a , Values: [1]
5) Spark Transformations
-RDD are immutable (no transactional)
-Never modify RDD in place.
-Transform RDD to another RDD to final result (by reducer)
-Create RDD
1)map: apply function to each element of RDD
함수를 적용하는 것으므로 이 트랜스포메이션 자체로는 아무런 동작을 하지 않는다! 수행 계획을 세울뿐..
def lower(line):
return line.lower()
lower_text_RDD = text_RDD.map(lower)
partitions are chunks of our data.
Partitions -> Map() -> Partitions (between same size of partitions)
-flatMap
def split_words(line):
return line.split()
words_RDD = text_RDD
flatMap(split_words)
words_RDD.collect()
-Transformations
| map(func) | Return a new distributed dataset formed by passing each element of the source through a function func. |
| filter(func) | Return a new dataset formed by selecting those elements of the source on which func returns true. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| mapPartitions(func) | Similar to map, but runs separately on each partition (block) of the RDD, so func must be of type Iterator<T> => Iterator<U> when running on an RDD of type T. |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but also provides func with an integer value representing the index of the partition, so func must be of type (Int, Iterator<T>) => Iterator<U> when running on an RDD of type T. |
| sample(withReplacement, fraction, seed) | Sample a fraction fraction of the data, with or without replacement, using a given random number generator seed. |
| union(otherDataset) | Return a new dataset that contains the union of the elements in the source dataset and the argument. |
| intersection(otherDataset) | Return a new RDD that contains the intersection of elements in the source dataset and the argument. |
| distinct([numPartitions])) | Return a new dataset that contains the distinct elements of the source dataset. |
| groupByKey([numPartitions]) | 가장 많이 사용하는 메서드로, 값을 집계하려면 셔플을 해야한다. When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will yield much better performance. Note: By default, the level of parallelism in the output depends on the number of partitions of the parent RDD. You can pass an optional numPartitions argument to set a different number of tasks. pairs_RDD.groupByKey().collect() 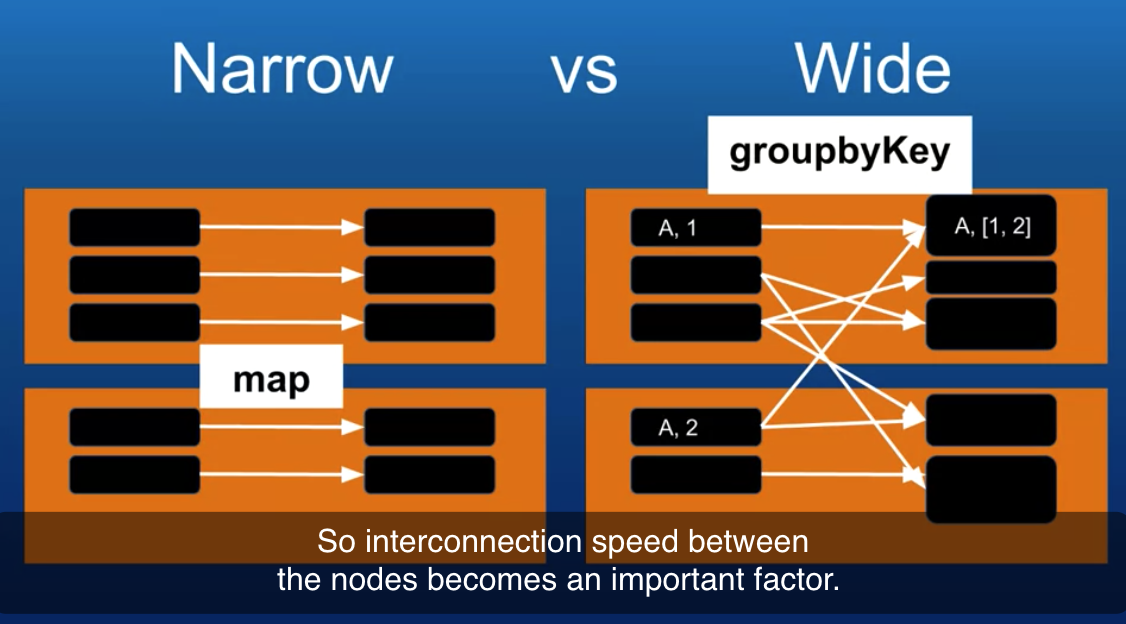 "shuffle" through the different nodes while groupbykey works. |
| reduceByKey(func, [numPartitions]) | 하나의 값이 나올때까지 반복적으로 키-값 쌍의 값에 이진 함수를 적용. 이 메서드는 스칼라 tuple2로 정의된 key-value 쌍의 RDD만 가능하다. 그러므로 이 연산을 수행하기 전에 RDD를 map() 메서드를 이용해서 먼저 키-벨류로 변환해줘야한다. When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]) | When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. Allows an aggregated value type that is different than the input value type, while avoiding unnecessary allocations. Like in groupByKey, the number of reduce tasks is configurable through an optional second argument. |
| sortByKey([ascending], [numPartitions]) | When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order, as specified in the boolean ascending argument. |
| join(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin, rightOuterJoin, and fullOuterJoin. |
| cogroup(otherDataset, [numPartitions]) | When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>, Iterable<W>)) tuples. This operation is also called groupWith. |
| cartesian(otherDataset) | When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). |
| pipe(command, [envVars]) | Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process's stdin and lines output to its stdout are returned as an RDD of strings. |
| coalesce(numPartitions) | Decrease the number of partitions in the RDD to numPartitions. Useful for running operations more efficiently after filtering down a large dataset. ex) sc.parallelize(range(10),4).glom().collect() out[]: [[0,1],[2,3],[4,5],[6,7,8,9]] ex) sc.parallelize(range(10),4).coalesce(2).glom().collect() out[]: [[0,1,2,3],[4,5,6,7,8,9]] by glom().collect() we can find our this data set was split in 4 partitions  |
| repartition(numPartitions) | Reshuffle the data in the RDD randomly to create either more or fewer partitions and balance it across them. This always shuffles all data over the network. ( even distributions of your cluster) <-> Coaleace does locally 1) Try with coalesce.. if the local merging of partitions is good enough for my app 2) Use repartition |
| repartitionAndSortWithinPartitions(partitioner) | Repartition the RDD according to the given partitioner and, within each resulting partition, sort records by their keys. This is more efficient than calling repartition and then sorting within each partition because it can push the sorting down into the shuffle machinery. |
reference: https://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
-groupByKey + reduce vs reduceByKey
reduceByKey:
improve this by doing first sum before transfer through the network.
-saveAsTextFile() 메서드는 스파크 잡을 즉시 실행한다. 반환값이 없어도 RDD를 계산하여 결과 파티션을 output directory에 파일로 기록한다.